Tato bakalářská práce se zaměřuje na využití velkých jazykových modelů (LLM) pro extrakci informací s aplikacemi ve znalostních grafech. V teoretické části je provedena rešerše na využití a definování extrakce informací. Dále je provedena rešerše na téma znalostních grafů s příklady využití jazykových modelů. Část je věnována datovým zdrojům a jejich důvěryhodnosti.
Práce popisuje rozdíly mezi méně výkonnými a více výkonnými jazykovými modely, které se mohou projevovat například rychlostí generování odpovědí nebo kvalitou usuzování.
Praktická část se věnuje validačnímu skriptu pro verifikaci RDF tvrzení z portálu Wikidata. Byl zjištěn aktuální stav jazykových modelů s ohledem na extrakci informací a znalostní grafy.

Teoretické základy
Extrakce informací
V teoretické části je provedena rešerše na využití a definování extrakce informací. Extrakce informací je klíčovou oblastí zpracování přirozeného jazyka, která se zabývá automatickým získáváním strukturovaných informací z nestrukturovaných nebo polostrukturovaných textových dat.
Znalostní grafy
Dále je provedena rešerše na téma znalostních grafů s příklady využití jazykových modelů. Znalostní grafy představují způsob reprezentace informací ve formě sítě entit a jejich vztahů, což umožňuje efektivní dotazování a odvozování nových poznatků.
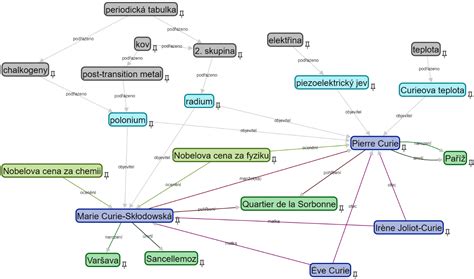
Datové zdroje a jejich důvěryhodnost
Část je věnována datovým zdrojům a jejich důvěryhodnosti. V kontextu extrakce informací a budování znalostních grafů je klíčové zvažovat spolehlivost a přesnost dat, která jsou pro tyto účely využívána.
Praktická implementace a validace
Validační skript pro Wikidata
Praktická část se věnuje validačnímu skriptu pro verifikaci RDF tvrzení z portálu Wikidata. Wikidata je otevřená, kolaborativní znalostní báze, která slouží jako zdroj strukturovaných dat pro různé aplikace, včetně těch založených na velkých jazykových modelech.

Porovnání jazykových modelů
Práce popisuje rozdíly mezi méně výkonnými a více výkonnými jazykovými modely, které se mohou projevovat například rychlostí generování odpovědí nebo kvalitou usuzování. Tato zjištění jsou relevantní pro výběr vhodného modelu pro konkrétní úlohu extrakce informací.
Implementace a testování
Nakonec byl implementován skript v jazyce Python, který byl otestován na 3 Wikidata subjektech za použití jazykových modelů ChatGPT-3 a ChatGPT-4. Testování umožnilo porovnat výkon a schopnosti těchto modelů v kontextu extrakce informací z databáze Wikidata.
ChatGPT 5.2 – nejnovější AI model je tady, je nejlepší? | Tomáš AI
tags: #damian #petr #bakalarska #prace