Předmět je úvodem do široké oblasti umělé inteligence a poskytuje potřebné základy pro návrh algoritmů pro řízení strojů. Navazuje na znalosti prohledávání stavového prostoru a rozšiřuje je uvažováním nejistoty v přechodech mezi stavy. Předmět představuje i základy posilovaného učení pro problémy, kde o přechodech mezi stavy nic nevíme. Poslední část předmětu představuje Bayesovskou rozhodovací úlohu a učení s učitelem, které je demonstrováno na lineárních klasifikátorech různých typů.
Základní úlohou rozpoznávání je nalezení strategie rozhodování minimalizující ztrátu plynoucí z chybných rozhodnutí. Potřebná znalost o (typicky statistickém) vztahu příznaků, t.j. pozorovatelných vlastností objektů a skrytých parametrů objektů z dané třídy je získána učením. Jsou představeny základní formulace úlohy rozpoznávání a principy učení.
Tento předmět je také součástí meziuniverzitního programu prg.ai Minor. Ten spojuje to nejlepší z výuky AI v Praze s cílem poskytnout studujícím hlubší a širší vhled do oboru umělé inteligence.
Obsah předmětu
- Úvod. Formulace úloh řešených v rozpoznávání. Mapa předmětu.
- Bayesovská úloha rozhodování, tj. čl. plynoucí z chybných rozhodnutí.
- Odhady parametrů pravděpodobnostních modelů.
- Lineární klasifikátor.
- Učení jako kvadraticky optimalizační problém.
- Učení metodou backpropagation.
- Druhý průchod učivem.
Cíle a metody
Předmět hluboce a obohacuje znalosti AI získané v bakalářském kurzu Kybernetika a umělá inteligence. Studenti získají přehled o dalších metodách používaných v AI a získají s nimi praktické zkušenosti. Osvojí si další požadované schopnosti pro budování inteligentních agentů. Aplikací nových modelů si zopakují základní principy strojového učení, techniky pro hodnocení modelů a metody pro prevenci přeučení. Dozvědí se o plánování a úlohách rozvrhování a o metodách, které se k jejich řešení používají. Studenti se také seznámí se základy pravděpodobnostních grafických modelů, Bayesovských sítí a Markovových modelů a naučí se jejich aplikace.
Studenti řeší několik rozpoznávacích úloh, např. klasifikaci některých písmen na registračních značkách automobilů. Předpokládáme, že značka byla již nalezena. Obrázky písmen jsou normalizovány na velikost 10×10 pixelů. K dispozici máte trénovací data, která byla náhodně vybrána. Jasové hodnoty pixelu jsou přerovnány do řádkových vektorů po sloupcích. Co řádek ve vstupním MAT-souboru, to jeden obrázek. Soubor train.mat obsahuje příznakové vektory, soubor train_labels.mat pak odpovídající označení tříd. Obrázky jsou pouze pro náhledy, rozhodující jsou data v MAT-souborech. Výsledek klasifikace bude ve stejném formátu jako proměnná v train_labels.mat. Obrázky v řádcích v train.mat odpovídají popiskům v train_labels.mat. Je dobré si uvědomit, že to je obvykle vše, co dá zákazník k dispozici. Poté, co připravíte kód, zákazník, kterého v tomto případě představuje cvičící, přinese testovací data, na kterých vaši práci ohodnotí. Testovací data budou v souborech test.mat, respektive test_labels.mat.

Prerekvizity a hodnocení
V kurzu očekáváme základní znalost lineární algebry. Budeme také potřebovat něco málo z teorie pravděpodobnosti a statistiky; tyto znalosti vám poskytneme přímo v kurzu.
Hodnocení bude složeno ze 3 základních komponent: práce během semestru, test v průběhu semestru (midterm) a závěrečná zkouška.
Práce během semestru
- Samostatné úlohy (45 minut).
- Během semestru je možné získat bonusové body za úspěšné vyřešení kvízů či diskuze na cvičeních. Tyto body vám mohou pomoci vylepšit celkový součet.
- Docházku budeme sledovat především pro naši potřebu, např. pro zapamatování jmen.
- Předpokládáme, že diskuse nad problémy a konzultace k úlohám budou probíhat především na cvičení.
- Konzultace mimo dobu cvičení na vyžádání.
- Malé úlohy a kvízy nebudou nahrazovány.
Pro účast na zkoušce je třeba mít udělený zápočet.
Praktické úlohy a nástroje
Studenti si znalost procvičí na semestrálních úlohách, v nichž budeme používat Python, který si studenti mohli osvojit v předmětech B3B33ALP, B4B33RPH, nebo BAB37ZPR.
Při řešení praktických úloh strojového učení máme často k dispozici více klasifikátorů a musíme se rozhodnout, který je nejvhodnější pro danou úlohu. V zip balíčku je soubor (odkaz je níže), se kterým budete při řešení úlohy pracovat. Předpokládá se, že k řešení úlohy bude použit Python.
Do odevzdávacího systému se odevzdává pdf report a implementace související s částí Hlavně bezpečně. Celková délka reportu by měla být rozhodně kratší než dvě strany A4.
Příklad úlohy: Klasifikace a optimalizace parametru
Mějme 5 různých natrénovaných binárních klasifikátorů. Výsledek klasifikace každého z klasifikátorů je závislý na hodnotě parametru $\alpha$. Všechny klasifikátory pustíme na testovací množině $X$. Zároveň vyzkoušíme všechny přípustné hodnoty parametru $\alpha$. Pro klasifikátor $i$ dostane tabulku s hodnotami $C_i(\bf x_j,\alpha_k)\in \{0,1\}$.
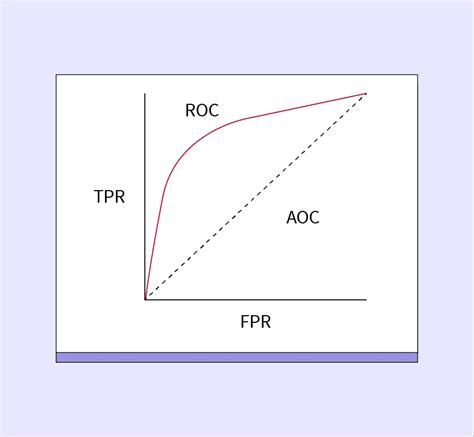
Pro klasifikátor 1 určete, která hodnota parametru $\{\alpha_0, \alpha_1, \dots, \alpha_{49}\}$ je nejvhodnější. Uvědomte si, že zatím nevíte, pro jakou konkrétní úlohu bude dán klasifikátor použit, a proto je nutné použít dostatečně obecnou úvahu. V krátkém pdf reportu vaší volbu parametru zdůvodněte (užijte pojmy jako např. sensitivita, falešně pozitivní, ROC křivka atd.). Do reportu také vykreslete ROC křivku a na této křivce znázorněte bod, který odpovídá optimální hodnotě parametru.
Příklad úlohy: Bezpečnostní klasifikace
Nyní si představte, že jste agent/ka 00111 a chcete k zabezpečení velmi tajných dokumentů použít svůj otisk prstu. Jedná se o velmi citlivá data, takže pokud nebudou kvalitně zabezpečena, tak bude lepší je zničit. K odemčení dat je vždy dostatek času. K dispozici máte 5 natrénovaných klasifikátorů (s různými hodnotami parametru $\alpha$). Všechny klasifikátory byly otestovány na testovací množině pro všechny hodnoty parametru $\alpha$. Výsledky testu pro jednotlivé klasifikátory jsou uloženy v tabulkách.
Vyberte vhodný klasifikátor a jeho parametr $\alpha$. Tato část navazuje na předchozí část Přísně tajné!. Váš kolega, také agent, se nabídne, že vám poskytne svůj klasifikátor, který je opět závislý na parametru $\alpha$. Protože není jisté, jestli se nejedná o dvojitého agenta, tak bude dobré nejdříve zjistit, jestli je klasifikátor lepší než klasifikátor vybraný v předchozí části. Z bezpečnostních důvodů bude muset rozhodnutí provést předem vytvořená funkce.
Doporučená literatura
- S. Russel, P. Norvig: Artificial Intelligence - A Modern Approach, 3rd ed., 2010
- Christopher M. Bishop. Pattern Recognition and Machine Learning.
- T.M. Cover and P.E. Hart. Nearest neighbor pattern classification.
- Richard O. Duda, Peter E. Hart, and David G. Stork. Pattern classification. Wiley Interscience Publication.
- Vojtěch Franc and Václav Hlaváč. Statistical pattern recognition toolbox for Matlab. Czech Technical University, Prague, Czech Republic, June 2004.
- Michail I. Schlesinger and Václav Hlaváč. Ten Lectures on Statistical and Structural Pattern Recognition.